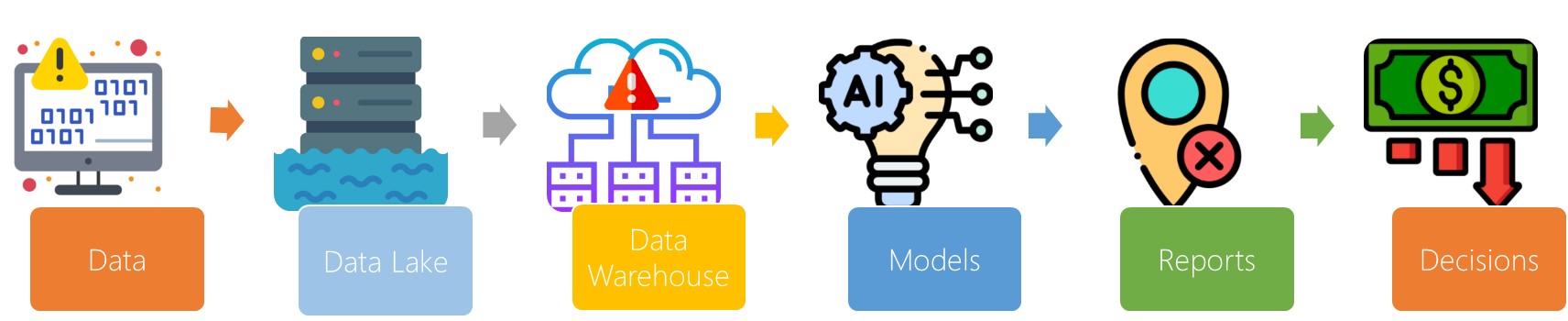
Data Observability is a pillar of DataOps
Data observability is the ability to track data and its flow throughout an organization. It provides a holistic view of data quality and can prevent data downtime and ensure consistency across IT systems. Data observability can be accomplished using a variety of methods including metrics, logs, traces, and analytics.
The first step in establishing data observability is to identify the data. Data can be viewed as columns or rows and is categorized by their schema. If there is an error in the data, it can be traced back to its source. Observability can be used to identify the root cause of downtime and determine what changes are necessary to prevent them.
Data observability refers to a set of practices that give a company enough context to resolve errors or detect problems. It’s the natural evolution of the DevOps movement and is one of the pillars of DataOps.
It improves data quality
Data Observabilityis the process of acquiring end-to-end real-time visibility into your data. It has become the buzzword of the IT world, and it can help you better understand your data pipelines and identify problematic areas. Observability gives data teams a 360-degree view of their data infrastructure, allowing them to identify and prioritize the sources of truth and identify problems before they become major problems.
Improving data observability is a great way to ensure data pipelines are reliable. This allows data teams to troubleshoot incidents faster. Time is critical when dealing with a data incident, and data observability can help you identify any issues in real-time. This enables you to improve data quality and speed up data adoption.
In today’s data environment, there are many data assets that need to be stored, processed, and analyzed. Many of these assets are dependent upon each other. Any change in one source can impact others, so it’s crucial to have complete and consistent visibility of your data stack. Improved data observability can help you make better decisions about what data you need to store, analyze, and utilize.
It increases productivity
Data observability is one of the most important aspects of modern enterprise data stacks. This technology helps organizations manage data resources and plan for future needs. It also improves data flow, increasing productivity and quality of data. When data is observable, it provides context for root cause analysis and remediation.
As data volume continues to grow, organizations need to keep an eye on what’s happening and when it’s happening. Data observability offers organizations an opportunity to quickly identify problems, and resolve them before they affect customers. The technology works by using lightweight instrumentation to capture data and stitch it together to provide a holistic view of distributed systems.
By improving data observability, organizations can create better relationships with clients, customers, and stakeholders. Observable data helps organizations adhere to service level agreements. These agreements ensure that the data exchanged is up-to-date, accurate, and compliant. Breaking these agreements can cost companies money and reputation, so ensuring data quality is critical to keeping them in business.
It helps prevent data downtime
The most important way to prevent data downtime is to have a framework in place that will allow you to monitor and track changes to data. Changes in data structure or schema can cause downtime, so you should implement data observability to monitor data changes. A good data observability framework will also be able to determine if bad data is being created or updated.
Data observability enables you to monitor data in real time and provides an audit trail of changes. This is critical for driving better data quality and ensuring valuable business insights. When you discuss data observability with your data engineering team, it is essential to start with specific business objectives. Then, you can evaluate your automation infrastructure to ensure that it can keep up with your changing data needs. Data observability is an essential tool to help prevent data downtime and improve data pipeline quality.
Observability allows you to run queries against data in relational databases and detect problems as they happen. It also helps prevent bad data from affecting your business. Data teams can monitor data quality and determine the root cause of any errors, so they can take action as quickly as possible. This not only prevents data downtime, but also saves valuable resources and time.